Projects
- K-State home
- K-State Olathe
- Research
- 1Data
- Projects
Projects designed to improve the quality of life for humans and animals are underway. 1Data collaborators include Majid Jaberi-Douraki, assistant professor of mathematics at the Institute of Computational Comparative Medicine at Kansas State University; Gerald Wyckoff, professor of molecular biology and biochemistry at the University of Missouri-Kansas City; and Jim Riviere, professor emeritus with the College of Veterinary Medicine at Kansas State University.
Below are summaries of projects inside the 1Data environment.
Investigating Drug Adverse Effect on Diabetes
Overview
With the efficacy and costs of medications rising rapidly, it is increasingly important to ensure that drugs be prescribed as rationally as possible. Recently, adverse drug effects have received intensive attention for it remains a leading cause of morbidity.
Our project, "Investigating the Adverse Drug Effect on Type-2 Diabetes and Breast Cancer," aims at finding out specific research questions as follows:
- Specific adverse effect of combination drugs since drugs and adverse effects are lumped together in the database;
- if adverse effect of drugs is observed in various visits of a patient;
- if adverse effect of drugs is correlated to dosage.
Our preliminary results demonstrated — see below — adverse effects of drugs are dependent on covariates such as age, gender and weight.
Further study on these covariates using propensity matching scores and other statistical methods are under investigation.
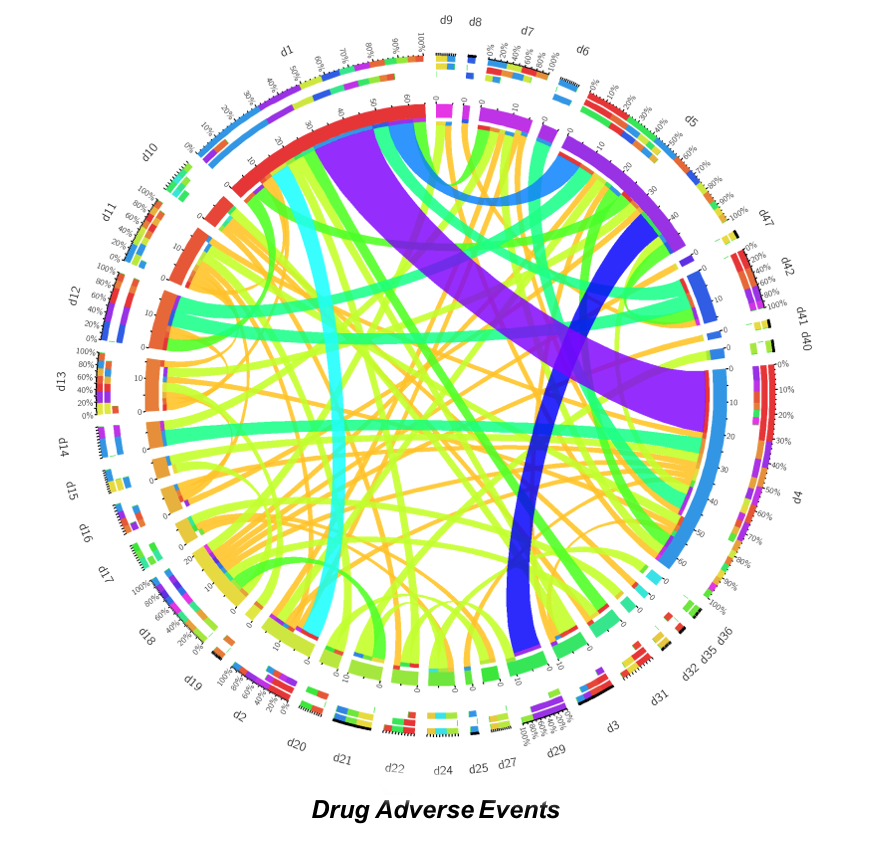
Project Update
1DrugAssist
1DrugAssist is an intelligent medicine recommender system that recommends drugs for patients who are suffering from various diseases. 1DrugAssist has been successfully upgraded to recommend drugs for patients who are suffering from either breast cancer or Type II diabetes.
More diseases will be added as the project progresses.
The system is currently in beta.
Analysis of Medical Care Data Base to Identify Comorbidity Patterns
Overview
Field of data analytics can immensely contribute to health care through analyzing clinical, patient behavior, sentiment and claims data. Most chronic health conditions such as diabetes accompany other complications and symptoms — hypertension, fatigue, etc. Finding associations between these conditions help us identify comorbidity patterns.
The primary goal of this study is to analyze and obtain insight into comorbidity or the coexistence of several diseases in patients using clinical data. Most studies that address comorbidity from the data analytics perspective use tools that investigate the occurrence of symptoms/diseases among a large population of patients. In this regard, if two diseases are observed together frequently, they are usually considered to have a causal or correlational relationship. While this method is able to successfully capture the correlation among diseases, it is highly prone to ignoring confounders or indirect correlations.
To explain this, let us consider a case where occurrences of three diseases, A, B and C, among a large patient sample are observed. Using traditional data analytics methods, we will find that A, B and C are all correlated. However, it is quite conceivable that these diseases correlate separately — for example, A correlates with B and B correlates with C. In this scenario, the correlations between A and B, and B and C have misguided the analysis method to conclude that there is a direct correlation between A and C.
In this study, we propose a novel angle for this problem by inferring the association patterns using binary Markov random fields (BMRF) that recreates the underlying comorbidity network of diseases through bootstrapping and cofactor elimination technique. BMRF are numerically efficient and statistically powerful in finding associations with removing confounders. Moreover, the least absolute shrinkage and selection operator in BMRF makes the results interpretable for the non-expert eyes. BMRF allow us to build a framework to perform statistical testing of various hypotheses about comorbidity patterns. Using our method, it is possible to obtain a more realistic picture of comorbidity and disease correlation and to infer an accurate comorbidity relationship among patients in different age, gender and race groups.
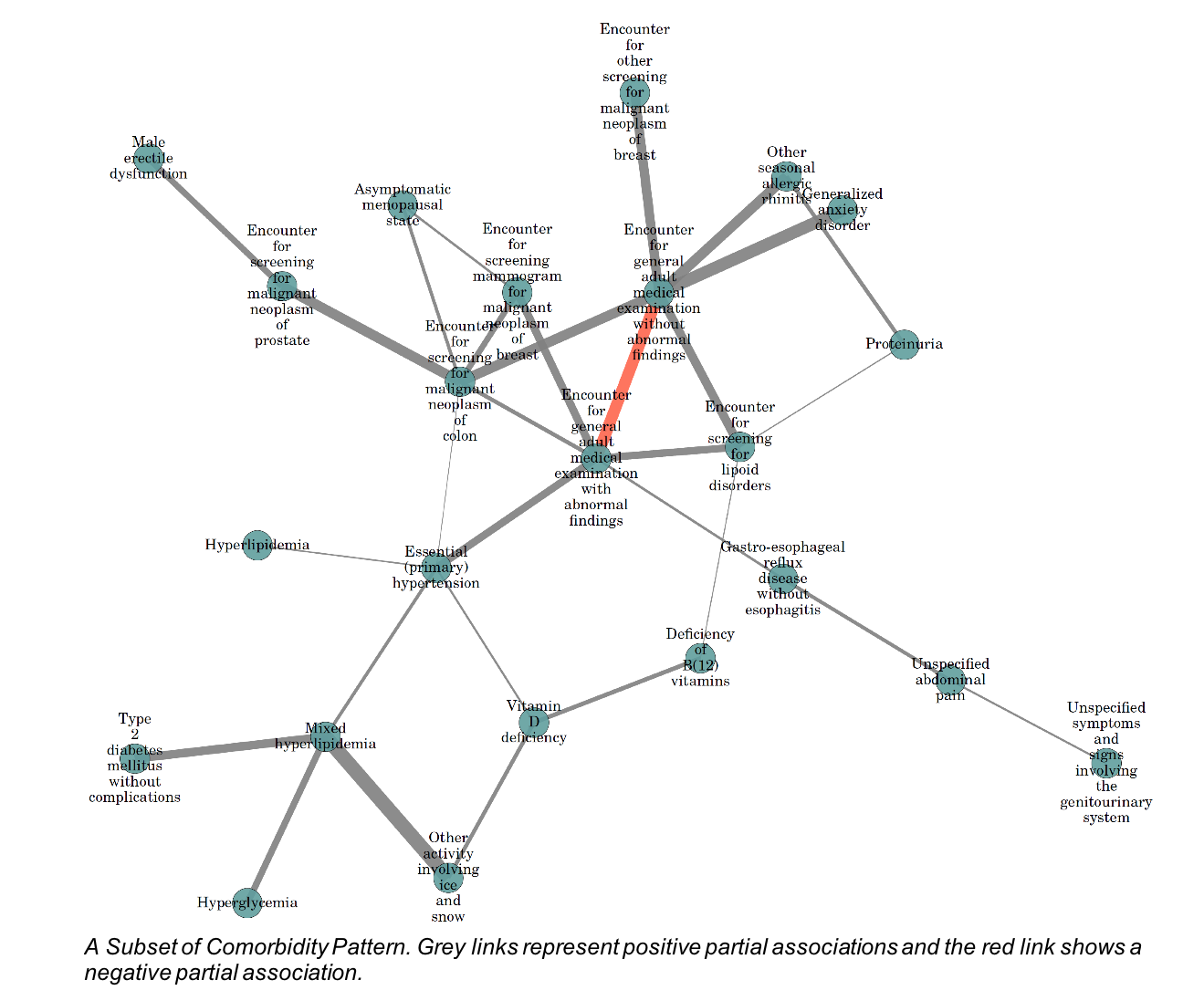
We illustrate the superiority of BMRF on state of the art data-mining methods by testing on benchmarks. Moreover, we analyze the patterns of International Statistical Classification of Diseases and Related Health Problems (ICD) in data collected from three general physician clinics in Maryland, in collaboration with Dr. Ardjmand from Frostburg State University. An excerpt of the found associations is depicted below.
Next phases of this study focus on investigating the structure of comorbidity network of diseases under different intervention methods. For this purpose, we measure the effects of medications on local comorbidity networks created by the aforementioned factor elimination method.
One potential outcome of this research is to identify the most effective intervention methods in terms of preventing comorbidity occurrences. Finding key explanatory indices for diseases is another pivot point of our research. A specific property measured in the lab may not directly correlate to a disease, but it can potentially provide necessary information to diagnose the disease.
This study strives to go beyond conventional correlational perspective among lab test results and diseases by exploring the sufficient and necessary conditions of a disease based on the lab results. In the course of conducting this study, no piece of information that reveals patients’ or doctors’ identity is needed nor will be used.
To conduct this study, the following data are analyzed:
- Demographic data: age, gender, etc.
- Clinical data including physician’s diagnoses (ICD codes and description), time of visits.
- Lab results.
Drugs prescribed or administered.
Creation of 1Data Ontology Fostering Data Sharing in Human and Animal Health Analytics
Overview
As defined by the U.S. Centers for Disease Control and Prevention, "The goal of One Health is to encourage the collaborative efforts of multiple disciplines-working locally, nationally and globally-to achieve the best health for people, animals and our environment."
However, the Kansas City Area Life Sciences Animal Health Working Group noted that interoperability between data sources was an impediment to such efforts, and therefore they created as a goal to "develop a computational concept to advance translational medicine approaches for human and animal health." We are creating the 1Data framework and database to solve this critical need in animal and human health analytics research and training.
The 1Data database is a collection of disparate data from various organizations worldwide. The main focus of the database is to accumulate diverse datasets from human and animal genomic, health and clinical science organizations to facilitate translational research efforts. By assimilating this data into one relational database, we can resolve the genomic relationship between animals in humans and the impact that data could have on the health sciences.
This framework also will allow for the development of a shared ontology that links human and animal health data — an ontology that, despite the proliferation of ontologies in the health sciences over the past two decades, still doesn't exist. Our goal is to utilize the accumulated, disparate data within the 1Data environment to create and train a neural network that will allow the rapid development and, perhaps more importantly, ongoing updating of this ontology.
The 1Data project is supported by data collected from a large number of public and private data sources and has received support from a number of KC-area institutions. Its formation is the result of a unique bi-state collaboration between UMKC and KSU, housed at KSU-Olathe.
Improving Rare and Orphan Disease Diagnostic Time and Enabling Therapy Development
Overview
Rare or orphan diseases, as defined by the U.S. Rare Disease Act of 2002, are those diseases that affect fewer than 200,000 inhabitants. While these diseases are individually quite rare, there are approximately 8,000 such diseases in the U.S., affecting in total approximately 10 percent of the population of the U.S. For the KC area, this means approximately 250,000 individuals are affected by rare diseases.
Treatment of these diseases is complicated by two factors: the average time to diagnose a rare disease (from symptom onset to diagnosis) is 4.8 years on average, and each disease is so rare that gathering a clinical sample for testing the efficacy of potential treatments is difficult.
In partnership with RareKC, a regional advocacy group for patients and their families affected by rare and orphan diseases, the 1Data structure aims to tackle this problem with three approaches.
First, we seek to create a best-in-class platform for patients and their families to share their experience with diseases, treatments, and advocacy.
Second, we seek to create a questionnaire powered by RedCap to capture the patient diagnostic odyssey, so that the common experience of patients across all rare and orphan diseases can be examined to identify discriminating factors that allow for more rapid diagnoses of these diseases.
Lastly, by typing these diseases — many of which have genetic components — to naturally occurring animal models of these diseases, we seek to create viable opportunities to test potential therapies in animal models, bolstering the research to enable these therapies to more quickly be moved towards approval in humans.
Assessing and Extending the Utility of Wearable Device Data for Service Animal Efficacy for U.S. Military Veterans with PTSD
Overview
Recent estimates suggest that more than 10 percent of recently returning veterans suffer from post-traumatic stress disorder (PTSD) to some degree or another. Service animals for the support of veterans with PTSD have been utilized, but there is a large gap in our knowledge of the efficacy of these animals, despite anecdotal evidence that these animals improve the lives of veterans in a meaningful way. This lack of "hard evidence" has made it difficult to develop funding sources, especially federal ones, for the funding of service animals for veterans with PTSD, with or without associate traumatic brain injury (TBI).
In analyzing this problem, a local solution existed that would allow the existing 1Data platform to collate information from human and dog wearables, from Garmin and FitBark, respectively.
By comparing data from these devices, synced to specific times, along with journal information from veterans, we can compare frequencies of interventions from animals with reports of efficacy and verify efficacy.
One key problem, for example, lies in the ability of animals to successfully intervene in interrupted sleep from nightmares/night terrors, where a successful effort by the animal might not be noted in journals but should be detected by a combination of information from the dog and human wearables However, this has not been examined. The 1Data framework should allow for the relatively easy integration and examination of this data.
Long-term, the goal of this project is to extend the utility of service animals by using data from their wearables to develop applications that monitor the dog activity and note cases where intervention and health checks for veterans would be indicated.